In a previous blog series, I analysed a database of 541,909 online transactions to explore which items were commonly purchased together. Today, we will be analysing the same dataset for a different purpose: to identify groups of customers with similar purchase behaviour so that we can market to each group most appropriately. See my Kaggle kernel for the full code.
Grouping data with similar characteristics into clusters is called cluster analysis. This is similar to classification, except we do not have a labelled dataset to use for training, and we do not know apriori the number of classes to use. Data points are simply grouped based on how similar they are to each other.
Since we do not have a training dataset, and are not supervising the algorithm’s learning, cluster analysis is an unsupervised algorithm.
Grouping customers into demographics is called customer segementation. There are many clustering techniques that can be applied – the simplest and most common is called k-means clustering.
In r, the function to apply the k-means algorithm is:
kmeans(x, centers, iter.max = 10, nstart = 1,
algorithm = c("Hartigan-Wong", "Lloyd", "Forgy",
"MacQueen"), trace=FALSE)The algorithm requires 2 arguments – the 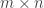
- Randomly assign each point to a cluster. This is the random aspect of the algorithm. To improve the odds of finding the best model, we can increase the number of times the algorithm runs. This is achieved by increasing the optional parameter nstart.
- Calculate the centroids of each of the two subgroups. In a k-means algorithm, this is achieved by taking the mean value of each of the points in the cluster for all
variables:
. Other variations of the algorithm, such as k-mediods and k-medians use other measures of centrality to compute the centroids.
- Assign each point to the cluster of the nearest centroid. ‘Nearest’ is measured using the Euclidean distance.
- This completes one iteration of the algorithm. Re-calculate the centroids and repeat. The algorithm is finished when no centroids move and no points change assignment. In general, k-means does not require a large number of iterations to converge. The default maximum number of iterations in r (iter.max) is 10. This can be increased to ensure convergence has been achieved.
Now that we understand how the algorithm works, let’s try it! For each customer, I have pre-computed some variables of interest:
- Number of orders placed
- Unique items purchased
- Total quantity of items purchased
- Average quantity of items per order
- Total money spent
- Average spent per order
This required quite a bit of data wrangling in dplyr to reshape the original transactional table this form. I will skip these steps here, but see my kaggle kernel for the full R script used.
First, we have to scale the data. To understand why, see the summary of the unscaled data:

Notice that total_money_spent contains much larger values than the other columns. If we applied k-means straight away to the unscaled data, total_money_spent would dominate the other columns, and our customers would predominantly be classified based on their total_money_spent.
The customer data is stored in a dataframe called customerlvl. Scaling the data:
km_data <- scale(customerlvl[2:7])We are now ready to run our k-means algorithm on km_data.
…but wait! There are 2 arguments required for kmeans(). How many clusters are we going to use?
Fortunately, there is a method of selecting the optimal number of clusters besides trial-and-error. We can construct a scree plot of total within cluster sum of squares (effectively the variance of our k-means model) against the number of clusters. Adding more clusters will always reduce the TWCSS, but we want to avoid unnecessary model complexity (‘overfitting’). We are looking for the minimum number of clusters needed to explain most of the variance.
As we will be repeating k-means with different numbers of clusters, we can remove the randomness from the iterations by setting a seed. We will examine up to 10 clusters:
set.seed(123)
k_max <- 10
twcss <- sapply(1:k_max, function(k){kmeans(km_data, k)$tot.withinss})Constructing the scree plot with ggplot2:
library(ggplot2)
g <- qplot(x = 1:k_max, y = twcss, geom = 'line')
g + scale_x_continuous(breaks = seq(0, 10, by = 1))We are looking for the ‘elbow’ within the plot, where the quality of the model no longer improves significantly as the model complexity increases.

This plot doesn’t have a clear elbow – there is a level of ambiguity. I will here select k=4. Later, when we test our model assumptions, we can examine whether this was an appropriate choice.
km <-kmeans(km_data, centers = 4, nstart=20)Examining some output:

We can see that we have 4 main groups of customers. However, remember that we scaled our data. This makes it really difficult to interpret how our different clusters of customers behave. Clusters 1 and 4 have an average number of orders that is negative – this does not make sense!
Let’s backtransform the centers onto the original scale so we can understand our 4 customer segments:
data.orig = t(apply(km$centers, 1, function(r)r*attr(km_data,'scaled:scale') + attr(km_data, 'scaled:center')))
- Cluster 1: The largest segment of our customers. They only place a few orders (on average 3.1 orders each) and have the smallest basket size – an average order for customers in Cluster 1 contains 152 items and costs $250.
- Cluster 2: 14 customers who purchase a huge volume of goods from us – these are likely large companies that rely on us as a supplier. These customers have spent an average of $110,489 in our store, and order frequently, having placed an average of 96 orders each. They purchase the widest variety of items – these customers have purchased an average of 720 unique items.
- Cluster 3: A large group of customers who order many different things across many different orders. Their purchase quantities, order sizes and spend amount are small.
- Cluster 4: 17 customers who don’t make many orders, but when they do, they are very large (an average of 3,279 items per order). This segment is also likely to be large companies that are supplied by us. However, they only purchase a few items from our catalogue (an average of 66 unique items).
Great! So we have analysed our 4 types of customers and are ready to start our marketing campaign … or are we? We jumped right into the algorithm without first assessing whether a k-means model is an appropriate model type for this data.
K-means relies on two underlying assumptions:
- The clusters are spatially grouped (or spherical).
- The clusters are of similar size (in terms of area, not cardinality).
When we observe the pairs() plot, we can see that both assumptions have been violated. The cluster regions are not spherical (or even elliptical), and the black cluster is far more sparse than the blue cluster.

In the next post in this series, I will explore some 2-dimensional examples to demonstrate where k-means clustering can go wrong, and demonstrate some pre-clustering diagnostics for n-dimensional data to determine whether k-means is appropriate.










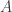 be a frequent itemset with support threshold
be a frequent itemset with support threshold  and let
and let  . Since
. Since  . But
. But  is a subset of
is a subset of  , so
, so  , so Support(B) = Support(A)
, so Support(B) = Support(A)  and so
and so 

 be any subset of items. Then the support count of
be any subset of items. Then the support count of  , is given by
, is given by  .
. , is given by
, is given by  .
. .
. is greater than or equal to some minimum threshold.
is greater than or equal to some minimum threshold. where
where  are itemsets.
are itemsets. .
. denoted by
denoted by  , is given by
, is given by  .
.
 .
. .
. , is given by
, is given by  .
.
 .
. unique items, a brute-force search through all possible
unique items, a brute-force search through all possible 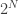 itemsets has
itemsets has  possible association rules where:
possible association rules where:
 . It is very computationally expensive to search such a large sample space.
. It is very computationally expensive to search such a large sample space.